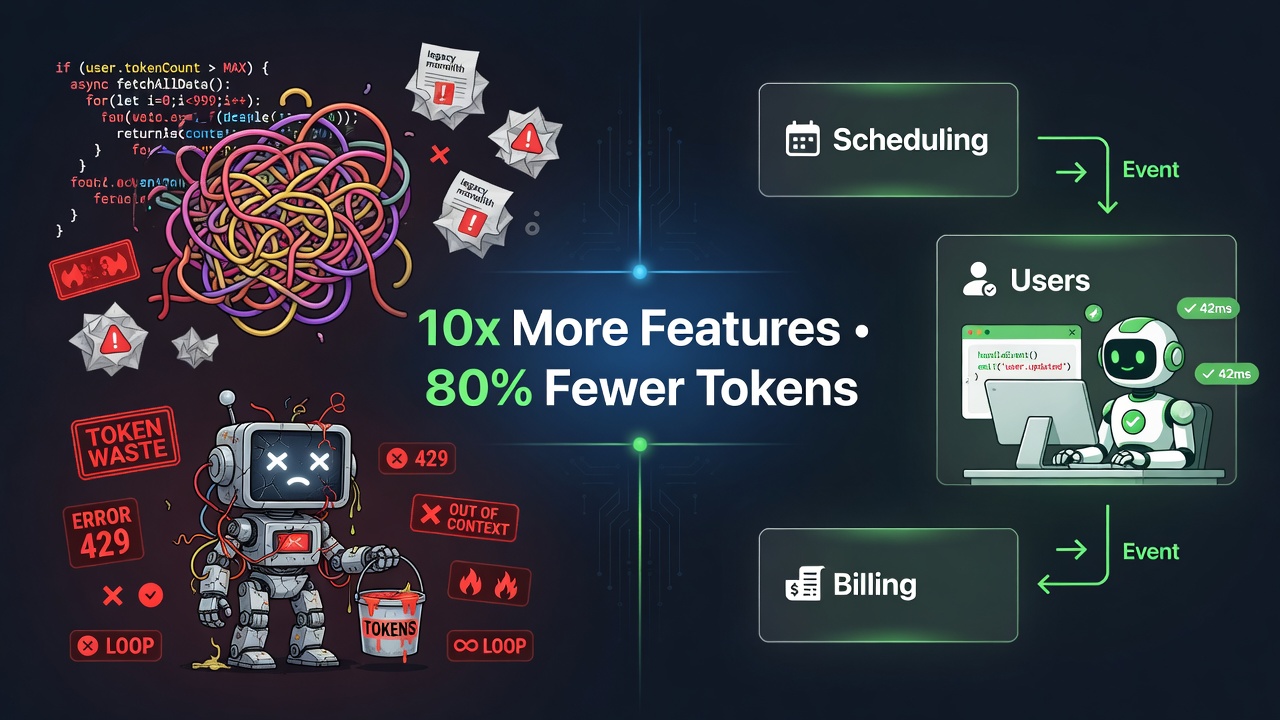
The AI reality check
You have the best models. Fable-class frontier systems with million-token context and near-perfect instruction following. You point them at your codebase and say "add a new scheduling feature with conflict detection and notifications."
In a typical layered monolith, the model still produces code that looks reasonable in isolation but breaks things it couldn't see. It uses an old user model from auth. It emits side effects that the analytics domain doesn't expect. It hard-codes assumptions about transaction boundaries that only exist in one other service. You burn through thousands of tokens just explaining the ripple effects, then more tokens fixing the fixes.
This happens even with the absolute best models available today. The model isn't stupid. It is simply forced to hold an entire undifferentiated system in its head to make one local change safely. That is the fundamental limit.
Architecture as the 10x multiplier (and why it compounds on tokens)
The developers extracting real 5-10x gains from the same frontier models aren't better at prompting. Their codebases are structured so the model only ever needs to see the relevant 1,000 lines instead of the irrelevant 15,000.
Real production data from a multi-tenant system built with heavy AI augmentation (AI responsible for the majority of new code across 12 domains):
| Metric | Typical monolith | Domain + event architecture |
|---|---|---|
| Effective context AI must load | 12k–20k+ lines | 700–1,200 lines per domain |
| Tokens spent per feature (Fable-class model) | 80k–250k+ | 12k–35k (mostly in one domain + events) |
| First-try merge rate | 35–45% | 85–92% |
| Human review + fix time | 25–60 min | 3–8 min |
| Features shipped per 1M tokens (cumulative) | ~4–7 | ~25–40 (and rising) |
| Velocity after 18 months on same product | Flat or declining | Still compounding |
The token effect is direct. Every feature in a clean domain costs dramatically fewer tokens because the agent isn't re-deriving the entire system state every time. It reads the local models, the local events it can emit or consume, and the type contracts. That's it.
This compounds. The first two domains require more hand-holding while you establish the patterns and the event vocabulary. By domain five or six, the agent has internalized the style through the architecture itself (types + event schemas + documentation in code). New features in existing domains or brand new domains cost less and less in tokens and human time.
Result: with a fixed token budget you ship more, or you can run agents for much longer sessions / more ambitious tasks before hitting walls. The same monthly spend that used to get you a handful of features now sustains a steady stream because waste has been architecturally removed upstream of any compression layer.
Domain boundaries: Why even Fable-class models need them
Give the absolute best model in existence a well-scoped domain and it becomes terrifyingly good. It can reason about all the invariants, all the edge cases that are actually relevant, and produce code that a senior engineer on that domain would have written.
Give it the whole tangled codebase and even Fable will:
- Violate cross-domain invariants it couldn't afford to keep in context.
- Re-implement logic that already exists three domains away.
- Emit events or side effects that no other part of the system is prepared for.
- Require you to spend most of the token budget just keeping it from breaking unrelated areas.
Contrast with a proper bounded context (real example structure used in production systems achieving the numbers above):
domains/scheduling/
models.py # 60 lines – only scheduling concerns
schemas.py # 50 lines – request/response shapes
service.py # 110 lines – the actual rules
events.py # what this domain publishes + what it subscribes to
__init__.py # the only thing other domains are allowed to import
tests/The agent is given the 800–1,200 lines that matter plus the event contracts. It can literally keep everything important in working memory. The output respects boundaries by construction. Integration is mostly "subscribe to the right events and publish the ones the contract promises."
Even the smartest model benefits enormously because you have removed the cognitive load of "what else might this touch?" That load is now carried by the architecture, not by the model's context window.
Events over calls: The decoupling that lets AI (and teams) evolve independently
In a call-heavy system, every new behavior requires modifying the originating service. When you add an AI agent that needs to react to "user deactivated," you change the user service. When another agent needs something else, you change it again. Over time the service becomes the bottleneck for all future work.
With events the originating domain only ever does one thing: publish a fact.
await event_bus.publish(
UserDeactivatedEvent(user_id=..., reason=..., occurred_at=...)
)Any number of subscribers — human teams, existing services, new AI agents, future open-source models — can react without ever touching the source. The contract is the event shape and its meaning, not the implementation.
This is exactly what allowed large organizations to keep multiple teams productive on the same complex product for 10–20 years. One team could rewrite their entire subsystem (or hand it off) while everyone else kept shipping, because they only depended on the events, not on internal details.
With AI the same isolation becomes even more valuable. You can spin up specialized agents per domain. You can replace one agent's model with a better one (or a local one) without touching the rest of the system. The architecture itself becomes the long-term interface that survives model generations.
Why this still matters when you go fully offline with open-source models
The best frontier models will always have larger context and better reasoning than local ones for the foreseeable future. That makes the architecture argument stronger, not weaker.
Local/open-source models typically have:
- Smaller practical context windows (even if the paper number looks big, effective reasoning drops off).
- Weaker long-horizon instruction following.
- No access to the absolute latest training data or fine-tunes.
In a monolith these limitations are fatal. The model literally cannot hold enough of the system to be safe. You are forced to do heavy retrieval or constant human guidance, which defeats much of the point.
In a properly bounded, event-driven system the same smaller model can be highly effective inside one domain. It only ever sees the 800–1,200 lines that are actually in scope plus the narrow event contracts. That is a problem it *can* solve well, even if it's not Fable-class.
The architecture also protects you from vendor risk and from model regression. When a new open-source model comes out that is better at your specific domain, you point it at that domain's context + events. You don't have to re-explain the entire company. When you decide to go air-gapped or cost-optimize, the same domains keep working.
In other words: clean domain isolation + events is what makes the intelligence layer swappable. The system outlives any particular model — cloud, open-source, or whatever comes after.
The only way forward
The physics of large systems has not changed. Adding vastly more powerful (or cheaper, or local) intelligence just makes the consequences of ignoring that physics arrive faster and at higher volume.
Start by drawing the domains and the events they exchange. Build the contracts and the type systems that make those boundaries enforceable. Only then turn the AI loose inside the guardrails.
Do this and even the current best models become dramatically more effective. Do this and tomorrow's open-source models (or the ones after) can still be productive participants instead of sources of expensive cleanup. Do this and you can keep shipping — with human teams, with AI agents, or with mixtures — for years instead of hitting the wall at 18 months.
The alternative is paying the full entropy tax on every token, every feature, every year, forever.
This is the same philosophy that makes tools like Slipstream powerful in an agent-heavy world: when the underlying system has clean domain boundaries and event contracts, the "context" an agent actually needs (and therefore the tokens it wastes) is already dramatically smaller. Architecture is the ultimate context compressor.